
はじめに
このようなブログを書いていると、史料の文字をテキストファイルに起こして調べることが多いのですが、画像ファイルの文字列を目で見てキーボード叩いて、と、人の手で作業するのはミスの原因であり、そもそも非効率です。
そこで出会ったのが、国立国会図書館が公開しているOCRライブラリでした。これは、国立国会図書館が史料の文字列をテキストデータ化するために開発されたもので、高性能且つ無料で公開されているのが最大の特徴です。
セットアップは、Quiitaにて投稿されていた、yanosen_jp様の記事を見て作業しましたので、そちらを見ていただけたらと思います。
さて、今回この記事で紹介するのは、テキストデータ化処理をワンクリックで動かそうというものです。
上に挙げた記事に掲載されていたタスクフローをコマンドプロンプトでバッチ化し、可能な限りユーザー操作を減らし、フォルダ管理もしやすいようにしました。
また、画像ファイル名を一括で採番するバッチも作ったので、合わせて皆さまの業務効率の改善に貢献できればと思います。
セットアップの注意点
前提として、PCの環境に、NVIDIAのドライバーが必要です。私は、これを見落としていて、セットアップ時のエラー調査に無駄に時間を浪費してしまいました(笑)。グラフィックボード搭載のPCは少々高価ですが、悪しからず。
Dockerコンテナのビルド
yanosen_jp様の記事にて1点補足です。
私用のPCでは、項目「Dockerコンテナのビルド」にて、エラーが発生したので、以下のようにコードを修正しました。
原因は、OS更新やpip仕様変更などの環境差で、ビルドロジックが壊れていました。この現象の再現は、個人差あると思います。一応、現象として掲載しておきます。
\ndlocr_cli\docker\Dockerfile
上記ファイルの21行目

あと、dockerbuild.batも修正したような気がします・・・
すいません記憶にないです(汗)
バッチのコード
ワードプレスでは、どうやらバッチファイルは掲載することができないらしいので、コードを生身で配置しました。テキストファイルに以下のコードを貼り付けて使ってください。
コード内の「①・②」は適宜、自身の環境に応じて修正してください。ディレクトリの指定箇所です。2か所のディレクトリを使います。
- Dockerで処理させる画像ファイルを保管するフォルダ[.images]、処理中に出力されるファイル・フォルダを保管するフォルダ[getDocker・getMain](同一ディレクトリ)
- 処理を終えた①を保管するフォルダ[任意のフォルダ名]
私の場合は、①として、Usersフォルダ直下に「.images」フォルダを、②として、OneDrive直下に「\ヲ_Docker管理」フォルダを作りました。
皆さんに修正していただくのは「①・②」と書いた部分のディレクトリだけなので、実際のロジックフローは解説しません。中身はコメント(REM ==)を見たり、AIに質問してください。
①テキストファイル(メモ帳・サクラエディタなど)に貼り付けて保存するとき、SJISで保存してください!UTFでは、文字化けします。
②Dockerアプリケーションを起動させた状態で実行してください
テキストデータ化.bat
@echo off
setlocal
REM ==========================
REM 1. 所定のフォルダに新規フォルダを作る
REM ==========================
REM ベースディレクトリ
set "oneDriveDirectory=C:\②\Docker管理"
REM チェック1(フォルダ名作成)==========================
:check1
echo.
set /p folderName=作成するフォルダ名を入力してください:
REM 空入力チェック
if "%folderName%"=="" (
echo フォルダ名が入力されていません。
goto check1
)
REM チェック対象フォルダ
set "checkFolder=%oneDriveDirectory%\%folderName%"
REM フォルダ存在チェック
if exist "%checkFolder%" (
REM 既にフォルダが存在する場合
echo.
echo 入力されたフォルダ名は既に存在します。
echo このまま実行しますか?フォルダ名を変更する場合はNを入力してください。
choice /c YN
if errorlevel 2 goto check1 REM N → 再入力へ
if errorlevel 1 goto check2 REM Y → 最終確認へ
) else (
REM フォルダが存在しない場合
echo.
echo 作成してよろしいですか? (Y/N)
choice /c YN
if errorlevel 2 goto check1 REM N → 再入力へ
if errorlevel 1 (
mkdir "%checkFolder%"
echo.
echo フォルダを作成しました:
echo %checkFolder%
)
)
REM チェック2(処理開始か否か)==========================
:check2
echo.
echo フォルダ「%folderName%」内で処理を開始してよろしいですか? (Y/N)
choice /c YN
if errorlevel 2 (
goto check1 REM 再入力へ
) else (
setlocal enabledelayedexpansion
REM 次の連番を決定(既存の 退避_1, 退避_2, ... の最大+1)
set "seq=1"
:find_next
if exist "%checkFolder%\退避_!seq!" (
set /a seq+=1
goto find_next
)
set "backupFolder=%checkFolder%\退避_!seq!"
REM 退避フォルダ作成
mkdir "!backupFolder!"
REM 退避対象外: 既存の 退避_* フォルダを /XD で除外してから MOVE
set "EXCLUDE_LIST="
for /d %%D in ("%checkFolder%\退避_*") do set "EXCLUDE_LIST=!EXCLUDE_LIST! "%%~nxD""
if defined EXCLUDE_LIST (
robocopy "%checkFolder%" "!backupFolder!" /E /MOVE /R:2 /W:2 /XD %EXCLUDE_LIST%
) else (
robocopy "%checkFolder%" "!backupFolder!" /E /MOVE /R:2 /W:2
)
echo 既に存在していたファイル・フォルダを「退避_!seq!」に退避させました。
endlocal
call :returnUsers
)
REM ==========================
REM 2. 作業ディレクトリへ移動
REM ==========================
cd /d ndlocr_cli
REM ==========================
REM 3. Dockerコンテナ起動
REM ==========================
REM 50ギガを割り当て、-i を削除
REM docker run --shm-size=50g --gpus all -d --rm --name ocr_cli_runner -v /C/①/.images:/root/tmpdir/img -i ocr-v2-cli-py38:latest
docker run --shm-size=50g --gpus all -d --rm --name ocr_cli_runner -v /C/①/.images:/root/tmpdir/img ocr-v2-cli-py38:latest
REM ==========================
REM 4. 追加バッチ実行
REM ==========================
:reTry1
call docker\run_docker.bat
if errorlevel 1 (
call :dockerStop
goto reTry1
)
REM ==========================
REM 5. Dockerにログイン(※ユーザー操作は不要のため、コメント)
REM ==========================
REM サイトは「-it」とあるが、これはユーザーに入力を求めるコマンド
REM バッチでは不要のため、コメント。
REM :reTry2
REM docker exec -it ocr_cli_runner bash
REM if errorlevel 1 (
REM call :dockerStop
REM goto reTry2
REM )
REM ==========================
REM 6. OCR実行
REM ==========================
REM 以下2行は1行にまとめ、自動化(なお、最後の exit は不要)
REM docker exec ocr_cli_runner rm -rf /root/tmpdir/output
REM docker exec ocr_cli_runner python main.py infer /root/tmpdir /root/tmpdir/output -s s
docker exec ocr_cli_runner sh -c "rm -rf /root/tmpdir/output && python main.py infer /root/tmpdir /root/tmpdir/output -s s"
REM ==========================
REM 7. OCR結果をホストへコピー
REM ==========================
docker cp ocr_cli_runner:/root/tmpdir/output C:\①\getDocker\
REM ==========================
REM 8. Usersディレクトリに戻る
REM ==========================
call :returnUsers
REM ==========================
REM 9. テキスト抽出&整理
REM ==========================
cd getDocker\tmpdir\txt
mkdir C:\①\getMain
for %%f in (*_main*) do xcopy "%%f" "C:\①\getMain" /Y
cd /d C:\①\getMain
REM ==========================
REM 10. Usersディレクトリに戻る
REM ==========================
call :returnUsers
REM ==========================
REM 11. 内容をひとつのテキストファイルに結合
REM ==========================
cd getMain
copy *.txt 結合後_main.txt
REM ==========================
REM 12. 内容をひとつのテキストファイルに結合
REM ==========================
call :returnUsers
REM ==========================
REM 13. .imagesを作成フォルダにコピー&中身削除
REM ==========================
REM 作成フォルダに .images をコピー(中身ごと)
xcopy /E /I /Y "C:\②\.images" "%checkFolder%\.images"
REM 元の .images の中身を削除(フォルダは残す)
for %%f in ("C:\①\.images\*") do del /Q "%%f"
for /D %%d in ("C:\①\.images\*") do rmdir /S /Q "%%d"
REM ==========================
REM 14. getDockerとgetMainを作成フォルダに移動(切り取り)
REM ==========================
if exist C:\①\getDocker (
move /Y C:\①\getDocker "%checkFolder%"
)
if exist C:\Users\HIS10923\getMain (
move /Y C:\①\getMain "%checkFolder%"
)
REM ==========================
REM 完了
REM ==========================
echo.
echo === 全処理完了 ===
echo 終了するには何かキーを押してください...
pause >nul
exit /b
REM ==========================
REM 共通処理
REM ==========================
REM エラーストップ
:dockerStop
docker stop ocr_cli_runner
goto :eof /b
REM Usersに戻る
:returnUsers
cd /d %USERPROFILE%
goto :eof /b
endlocal採番.bat
@echo off
setlocal enabledelayedexpansion
REM ===========================
REM 1. 候補フォルダ設定
REM ===========================
set "baseDir=C:\②\Docker管理"
:inputFolder
echo.
set /p userFolderName=処理対象のフォルダ名を入力してください:
if "%userFolderName%"=="" (
echo フォルダ名が入力されていません。
goto inputFolder
)
set "candidate1=%baseDir%\%userFolderName%"
set "candidate2=%candidate1%\.images"
set "candidate3=C:\①\.images"
REM サブルーチン定義をスキップしてメイン処理へ
goto :main_check
REM ===========================
REM 2. 画像カウント関数(フォルダがなければ count=-1)
REM ===========================
:countImages
REM 入力: %1 = フォルダパス
REM 出力: !count! に画像枚数、フォルダなしの場合 -1
if not exist "%~1" (
set count=-1
exit /b
)
set count=0
for %%x in (jpg jpeg png gif bmp) do (
for /f %%i in ('dir /b /a-d "%~1\*.%%x" 2^>nul ^| find /c /v ""') do (
set /a count+=%%i
)
)
exit /b
REM ===========================
REM 3. 候補フォルダのチェック
REM ===========================
:main_check
call :countImages "%candidate1%"
set "count1=!count!"
call :countImages "%candidate2%"
set "count2=!count!"
call :countImages "%candidate3%"
set "count3=!count!"
echo.
echo どのフォルダを処理しますか?画像ファイル数を確認してください。
echo 0: フォルダ名を再入力する
if !count1!==-1 (
echo 1: %candidate1% (フォルダなし)
) else (
echo 1: %candidate1% (!count1! 枚)
)
if !count2!==-1 (
echo 2: %candidate2% (フォルダなし)
) else (
echo 2: %candidate2% (!count2! 枚)
)
if !count3!==-1 (
echo 3: %candidate3% (フォルダなし)
) else (
echo 3: %candidate3% (!count3! 枚)
)
REM ===========================
REM 4. 選択受付
REM ===========================
:choose
set /p choice=選択してください (0/1/2/3):
if "%choice%"=="1" (
if !count1! lss 1 (
echo.
echo 選択できません。フォルダが存在しない、または画像が0枚です。
echo.
goto choose
)
set "checkFolder=%candidate1%"
set "imageCount=!count1!"
) else if "%choice%"=="2" (
if !count2! lss 1 (
echo.
echo 選択できません。フォルダが存在しない、または画像が0枚です。
echo.
goto choose
)
set "checkFolder=%candidate2%"
set "imageCount=!count2!"
) else if "%choice%"=="3" (
if !count3! lss 1 (
echo.
echo 選択できません。フォルダが存在しない、または画像が0枚です。
echo.
goto choose
)
set "checkFolder=%candidate3%"
set "imageCount=!count3!"
) else if "%choice%"=="0" (
echo.
echo 再入力に移動します。
goto inputFolder
) else (
echo.
echo 入力が正しくありません。0~3 のいずれかを入力してください。
echo.
goto choose
)
echo.
echo 選択したフォルダ: [%choice%] %checkFolder% (!imageCount! 枚)を実行してよろしいですか? (Y/N)
choice /c YN
if errorlevel 2 (
echo 再入力に移動します。
goto inputFolder
)
REM チェック2(処理開始か否か)===========================
:check2
echo.
set /p countStart=連番の開始番号を入力してください(整数):
REM 数字かどうかを正規表現でチェック
for /f "delims=0123456789" %%A in ("!countStart!") do (
echo エラー: 0以上の整数を入力してください。
goto check2
)
echo.
echo "%countStart%" から採番を開始します。よろしいですか? (Y/N)
choice /c YN
if errorlevel 2 (
echo.
echo 再入力に移動します。
goto check2
)
echo 処理を開始します・・・
REM ===========================
REM 5. 退避処理(連番付与前)
REM ===========================
setlocal enabledelayedexpansion
REM 次の退避番号を決定(既存の退避_* の最大+1)
set "seq=1"
:find_next
if exist "%checkFolder%\退避_!seq!" (
set /a seq+=1
goto find_next
)
set "backupFolder=%checkFolder%\退避_!seq!"
REM 退避フォルダ作成
if not exist "!backupFolder!" mkdir "!backupFolder!"
REM 画像ファイルのみ退避フォルダへコピー(退避_* サブフォルダは対象外)
set "backupCount=0"
for %%x in (bmp gif jpg jpeg png) do (
for /f "delims=" %%f in ('dir /b /a-d "%checkFolder%\*.%%x" 2^>nul') do (
copy /Y "%checkFolder%\%%f" "!backupFolder!\%%f" >nul
set /a backupCount+=1
echo 退避: %%f
)
)
echo.
echo 画像ファイル !backupCount! 件を「退避_!seq!」に退避しました
endlocal
REM ===========================
REM 6. 画像ファイルに3桁連番を付与してリネーム
REM ===========================
set /a counter=%countStart%
set /a startNum=%counter%
REM 元の名前を一時クリア用にリネーム
for %%x in (bmp gif jpg jpeg png) do (
for /f "delims=" %%f in ('dir /b /a-d "%checkFolder%\*.%%x" /on 2^>nul') do (
ren "%checkFolder%\%%f" "tmp_%%f"
)
)
REM 連番付与
set /a counter=%countStart%
set /a startNum=%counter%
REM 拡張子-ファイル名順
for %%x in (bmp gif jpg jpeg png) do (
for /f "delims=" %%f in ('dir /b /a-d "%checkFolder%\tmp_*.%%x" /on') do (
set "num=000!counter!"
set "num=!num:~-3!"
ren "%checkFolder%\%%f" "!num!%%~xf"
echo リネーム: %%f → !num!%%~xf
set /a counter+=1
)
)
set /a endNum=counter-1
echo.
echo すべての画像ファイルに連番を付与しました。
echo 開始番号 "%startNum%"、終了番号 "%endNum%"
REM ===========================
REM 完了
REM ===========================
echo.
echo === 全処理完了 ===
echo 終了するには何かキーを押してください...
pause >nul
endlocal
exit /b 0
「テキストデータ化.bat」の解説
①のディレクトリ直下「.images」にテキスト化したい画像ファイルを配置し、処理結果を②の任意のフォルダに格納する、といった運用を想定して作っています。
まず、①に処理したい画像を配置してください。
その次に、バッチファイルを叩いてください。バッチファイルを起動させたら、まず、②に新規フォルダを作るようにしています。要するに、事前に保存先を作っておく必要はないということです。あとは完了を待つだけです。
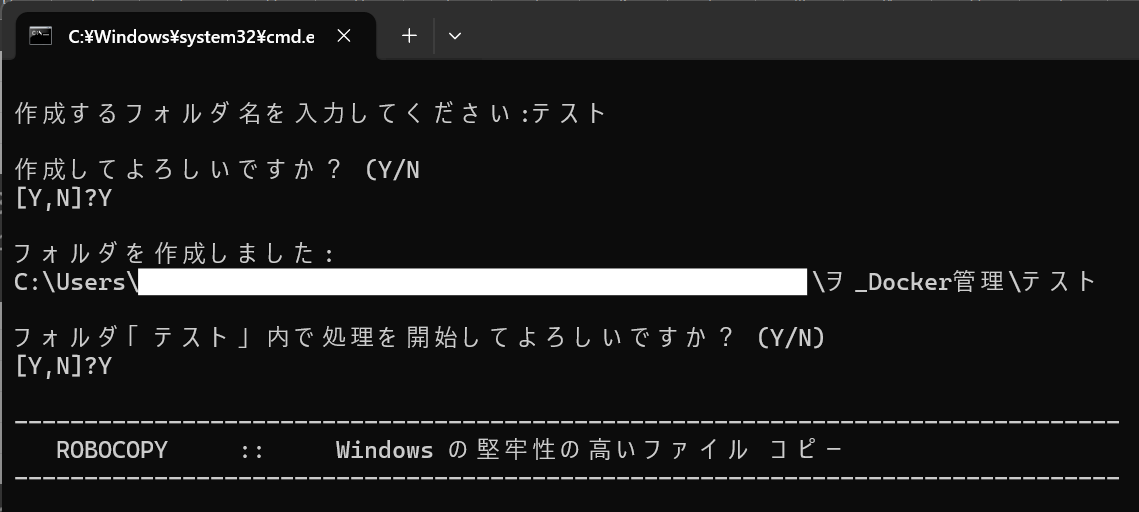
仮に、既に存在するフォルダで実行したい場合は、そのフォルダ名を入力してください。処理結果は、そのフォルダの直下に配置します。
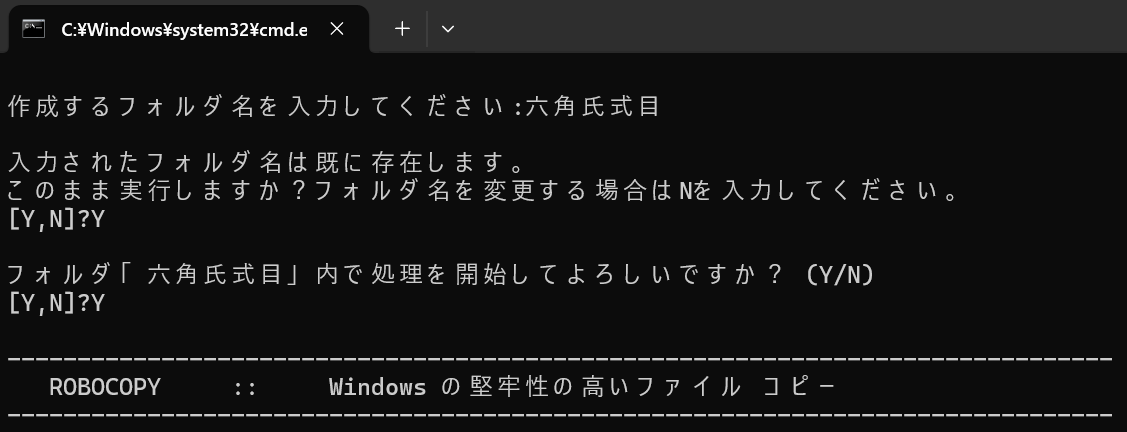
なお、既に直下にフォルダやファイルが存在したら「退避_n」(nは1から連番)フォルダを作成、退避させるようにしました。意図しない実行によるファイル・フォルダの紛失を防ぐためです。
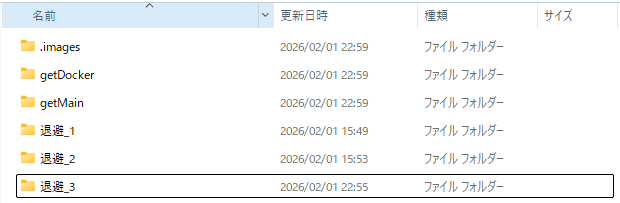
処理の流れを簡単に説明します。
バッチファイルを実行すると、①フォルダの「.images」のテキスト化の処理が走り、その過程、結果で「getDocker」「getMain」フォルダが「.images」フォルダと同一ディレクトリに生成されます。
それを、②のフォルダ内に、
「.images」はコピー・「getDocker」「getMain」は切り取り
で配置して処理完了。
といった流れです。
処理が完了したら、②フォルダ内に配置された、「getMain」フォルダを見に行きましょう。このフォルダの中にあるファイルがテキストデータ化されたファイルです。「結合後_main.txt」は、それらを1つにまとめたものになります。

「採番.bat」の解説
スクリーンショットや写真で撮った画像ファイルは、文字化けしていたり、取得日時がそのままファイル名になっていたりと、ファイル名が分かりづらいことがあります。
それは並び順が保証されないことを意味し、そのままテキストデータ処理を流すと、出力結果がおかしいことになりかねません。かといって、1ファイルずつ改名するのは面倒です。
そこで、指定した開始番号から連番を振る、採番バッチを作りました。これを流した後に、テキストデータ化バッチを流すと安全です。
どのフォルダに配置された画像ファイルを採番するか、3つの候補(+キャンセル)を設けました。
- 入力したフォルダ内
- 入力したフォルダ内にある「.images」フォルダ内
- 処理対象の「.images」フォルダ内(コード内の①のディレクトリのこと)
- キャンセル
処理前の「.images」(③)だけを処理対象にしても良かったのですが、とりあえずフォルダに保存したり(②)、処理後に採番したくなったり(③)、といった状況が、自分が作業する中で常にあったので、柔軟に対応するように仕様を変更しました。
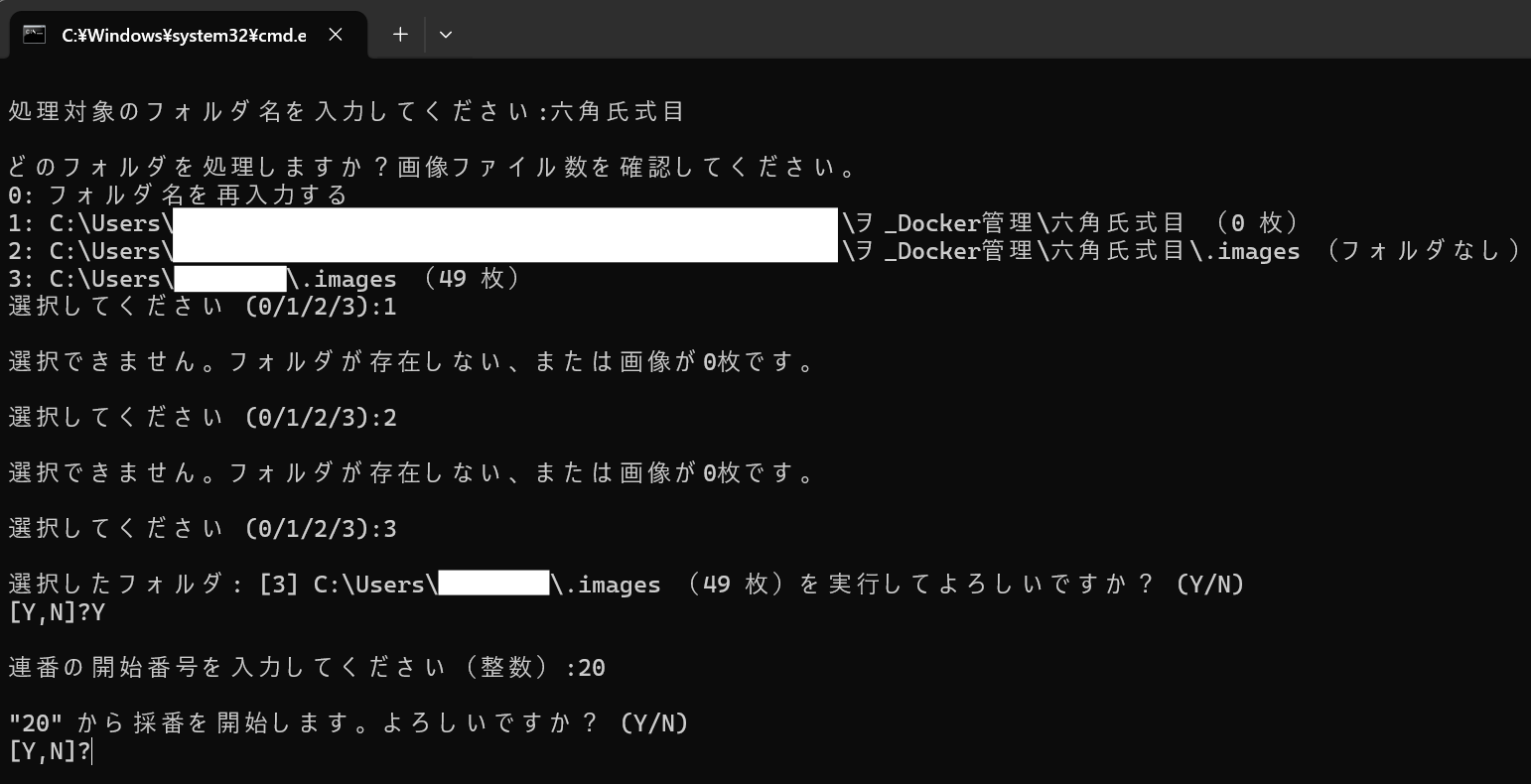
その柔軟性に対応するため、「テキストデータ化.bat」と違い、存在しないフォルダの入力を許容することとなりました。ただ、フォルダが存在しない、または画像ファイルが0枚の場合は、処理しないようにして、エラーを回避しています。
採番開始は、0を含む整数で設定してください。負の数は認めていません。
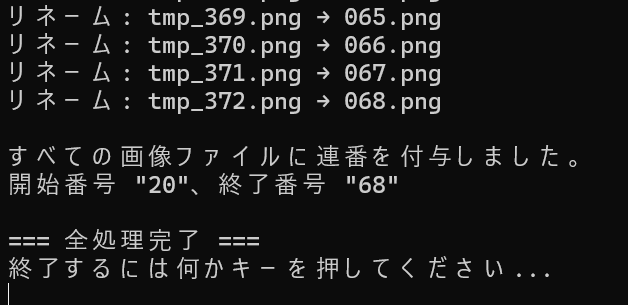
なお、採番の失敗を防ぐために、「テキストデータ化.bat」と同様、退避フォルダを作成してから処理を実行するようにしています(処理開始前に移行するので、ファイル名は元のまま)。
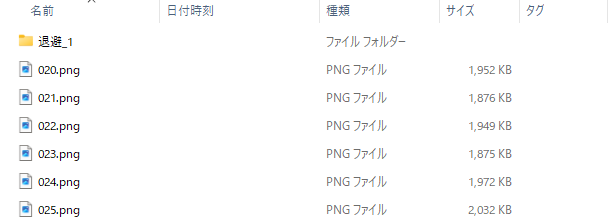
フォルダは採番対象外です。
終わりに
OCRによって、作業効率が数十倍、数百倍になりました。なんせ出力されたテキストの制度が高すぎます。手直しする作業が減るだけでなく、テキスト化作業そのものの作業が短縮されたので、管理しやすくなりました。
作っておいたマニュアルも開く必要なければ、エラー対応であちこちタブ移動する必要もなくなりましたからね。退避タスクを挟んでいることによって、戻り作業も発生しません。
良い仕事しました!
| 前の記事へ << | 次の記事へ >> |











